深度学习之卷积神经网络理论基础
卷积层的操作(Convolutional layer)
在提出卷积层的概念之前首先引入图像识别的特点
图像识别的特点
- 特征具有局部性:老虎重要特征“王字”仅出现在头部区域
- 特征可能出现在任何位置
- 下采样图像,不会改变图像目标
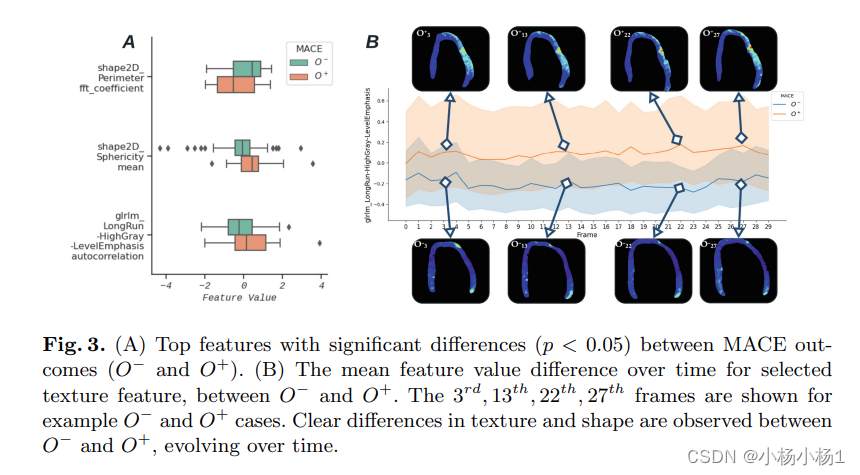
例如从512 * 512的图像进行下采样得到32 * 32的图像目标

- 特征具有局部性:卷积核每次仅连接K * K区域,K * K是卷积核尺寸
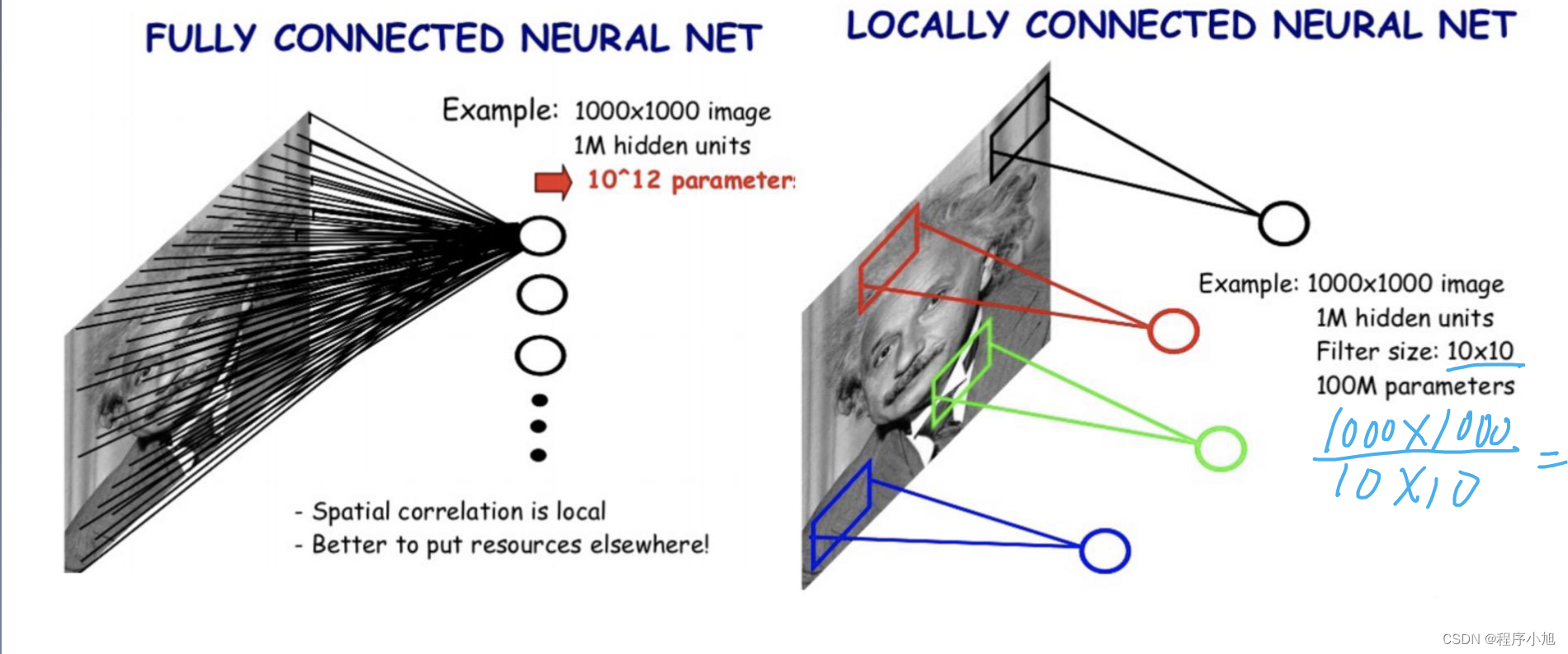
- 特征可能出现在任何位置:卷积核参数重复使用(参数共享),在图像上滑动

该图片的卷积的计算步骤如下所示:(即对应位置相乘在相加得到最终的结果)
0×0+1×1+3×2+4×3=19
1×0+2×1+4×2+5×3=25
3×0+4×1+6×2+7×3=37,
4×0+5×1+7×2+8×3=43
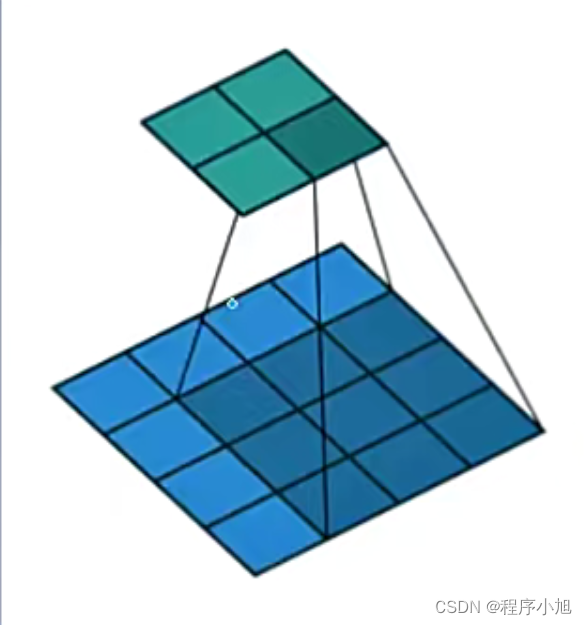
其中绿色代表的是输出部分,蓝色代表的是输入的部分,绿色的每一个区域是在蓝色区域的基础上经过卷积运算得到的,在计算的过程中区域不断的进行滑动
卷积层的相关概念
卷积核(Kernel):具可学习参数的算子,用于对输入图像进行特征提取,输出通常称为特征图(featuremaps)
通常我们说的就是3x3的卷积核,即对应上图中的核函数2x2的卷积核

卷积核当中的权重就代表的是一种特征模式。2012年AlexNet网络第一个卷积层卷积核可视化卷积核呈现边缘、频率和色彩上的特征模式。
填充(Padding) 在输入图像的周围添加额外的行/列。使卷积后图像分辨率不变,方便计算特征图尺寸的变化弥补边界信息丢失
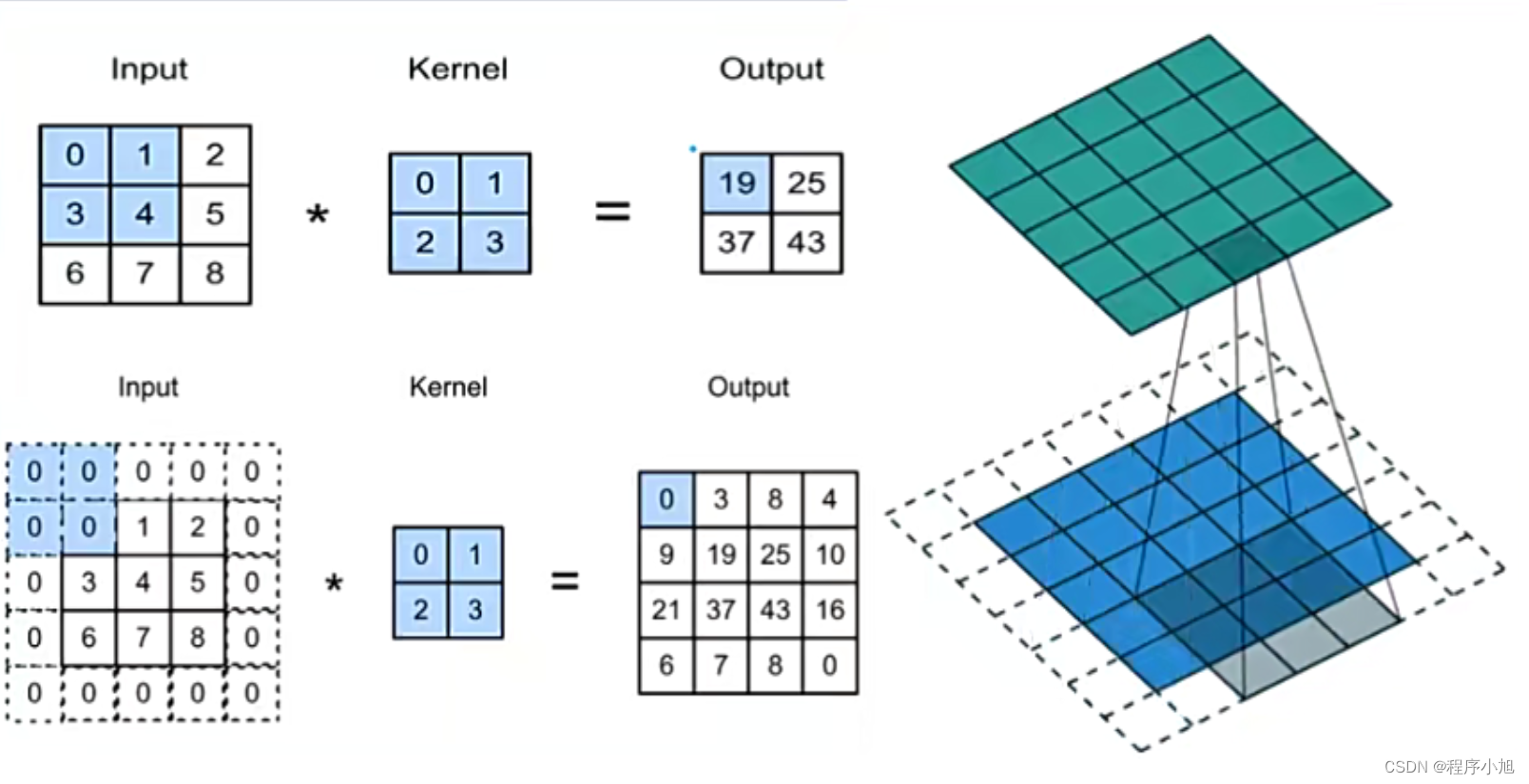
而该图中的padding=1 在上下左右都添加1个位置的像素,保证边缘部分与中间部分相比不会参与卷积的次数太少而被忽略而丢失
步长(Stride) :卷积核滑动的行数和列数称为步幅,控制输出特征图的大小,会被缩小1/s倍
在蓝色图像上每次滑动的距离之间影响得到的输出图的大小和像素值
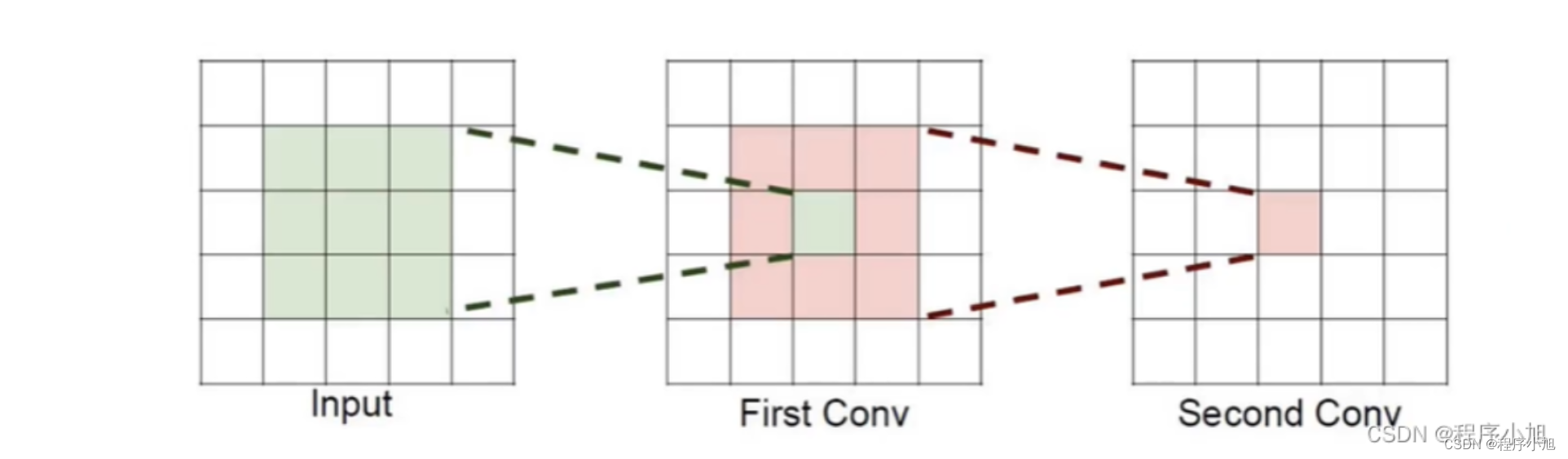
感受野:特征图中的一个点相当于图片中多大的区域,层数越多感受野越大。
感受野从3 * 3 到 5 * 5的区域
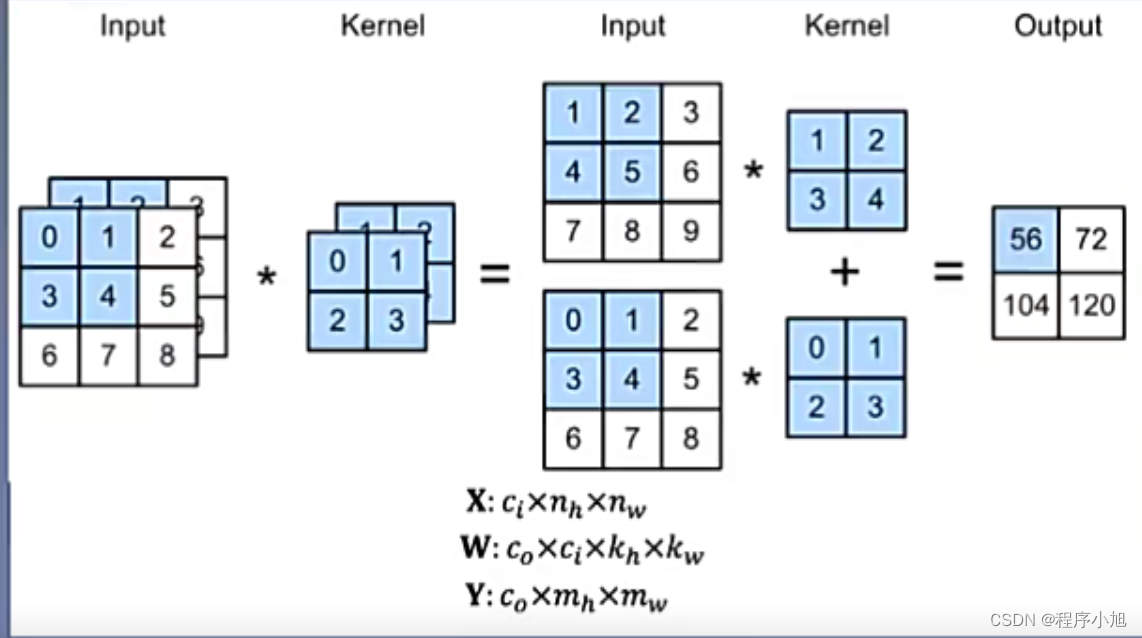
多通道卷积
多通道卷积:RGB图像是3 * h* w 的三维的数据,第一个维度3,表示channel,通道数一个卷积核是3-D张量,第一个维与输入通道有关注:卷积核尺寸通常指高、宽
补充:2-d卷积和3-d卷积的区分,卷积核在输入上只在行和列两个维度上移动并进行卷积—称为2d卷积 ,而在一些视频任务中在此基础上还需要使用到第三个维度即时间维度称为3-d卷积
池化层操作(Pooling layer)
- 下采样图像,不会改变图像目标:降低计算量,减少特征
池化:一个像素表示一块区域的像素值,降低图像分辨率
- 方法1:MaxPooling,取最大值(最大池化)
- 方法2:AveragePooling,取平均值(平均池化)
而池化层中无可学习的参数
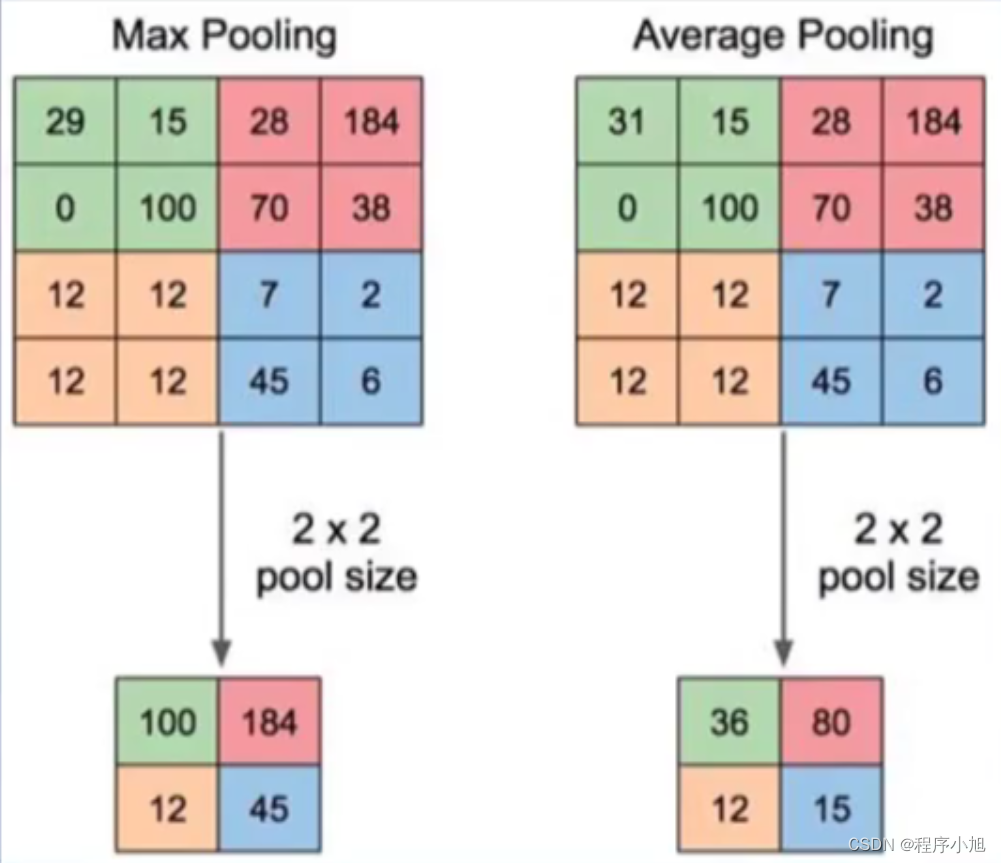
池化操作可以看作是一种特殊的卷积操作。
池化的作用:
- 缓解卷积层对位置的过度敏感。
Lenet -5
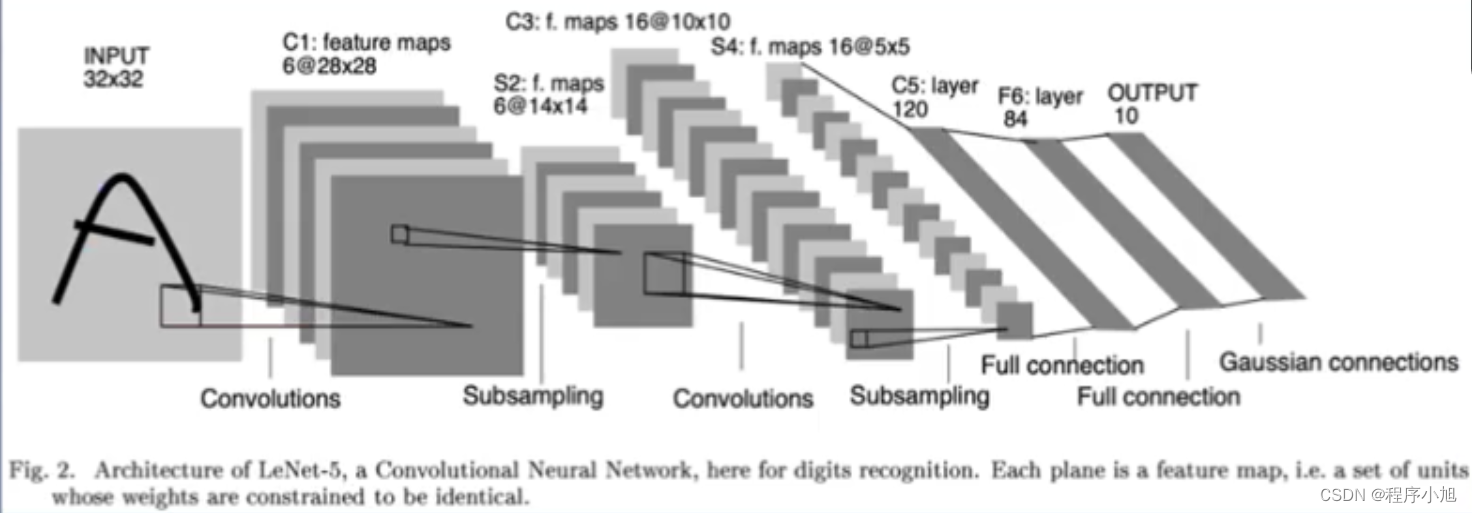
- C1层: 卷积核K1=(6,1,5,5),p=1,s=1,output=(6,28,28)
- S2层:最大池化层,池化窗口=(2,2),s=2,output=(6,14,14)
- C3层:卷积核K3=(16,6,5,5),p=1,s=1,output=(16,10,10)
- S4层:最大池化层,池化窗口=(2,2),s=2,output=(16,5,5)
- FC层:3个FC层输出分类
特征提取器:C1、S2、C3、S4分类器:3个FC

![[vue] nvm use时报错 exit status 1:一堆乱码,exit status 5](https://img-blog.csdnimg.cn/direct/c685891de8bd42b0a226106117c4baed.png)